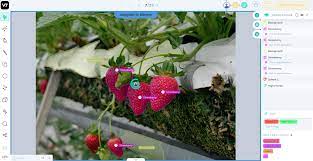
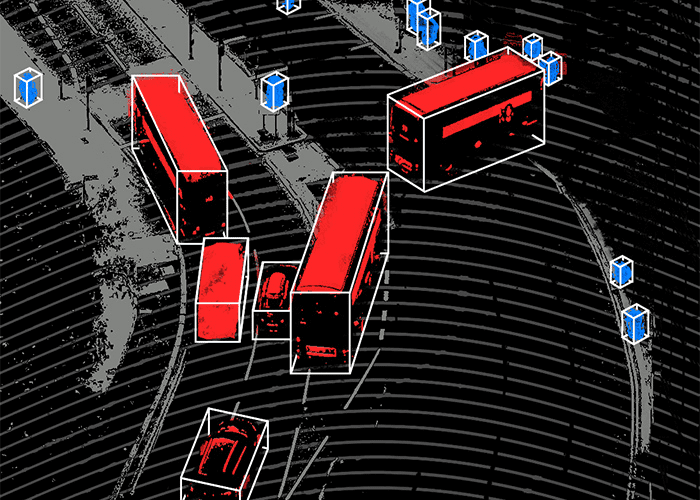
translation What is best Data Labeling and How to Do It Efficiently [Tutorial] March 30, 2024 No Comments
Services Best methods of data labeling (what are the main types of data labeling) February 2, 2023 No Comments
 1")