Skip to content
Home
Services
Localization
Translation Service
Multimedia Localization
Interpretation
Machine Learning Data Collection
Data Collection
Training Data Types
Data Annotation
AI Services
Speech Recognition
Image Identification
Natural Language Processing
Blog
About
Join our team
Menu
Home
Services
Localization
Translation Service
Multimedia Localization
Interpretation
Machine Learning Data Collection
Data Collection
Training Data Types
Data Annotation
AI Services
Speech Recognition
Image Identification
Natural Language Processing
Blog
About
Join our team
Contact Us
Blog
All Categories
annotations on a video
Case Study
Cost
data service
Datasets
Ebook
IT
Knowledge
Machine learnings
Services
Strategy planing
Taxes & Efficiency
translation
translators
Uncategorized
data service
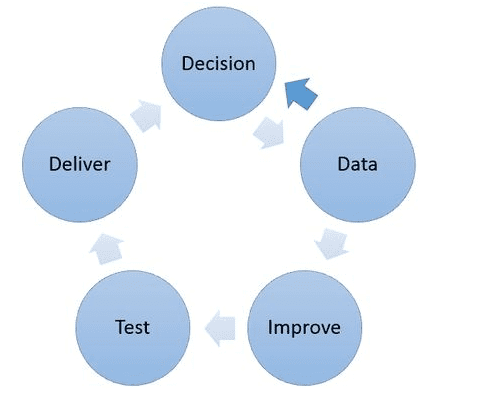
Robust and scalable Machine Learning lifecycle
September 5, 2021
No Comments
Datasets
Data Entry Services
September 5, 2021
No Comments
data service
WHY INDIA IS PREFERRED OUTSOURCING DESTINATION?
September 5, 2021
No Comments
data service
Big Data Testing Strategy
September 5, 2021
No Comments
 1")