 1")
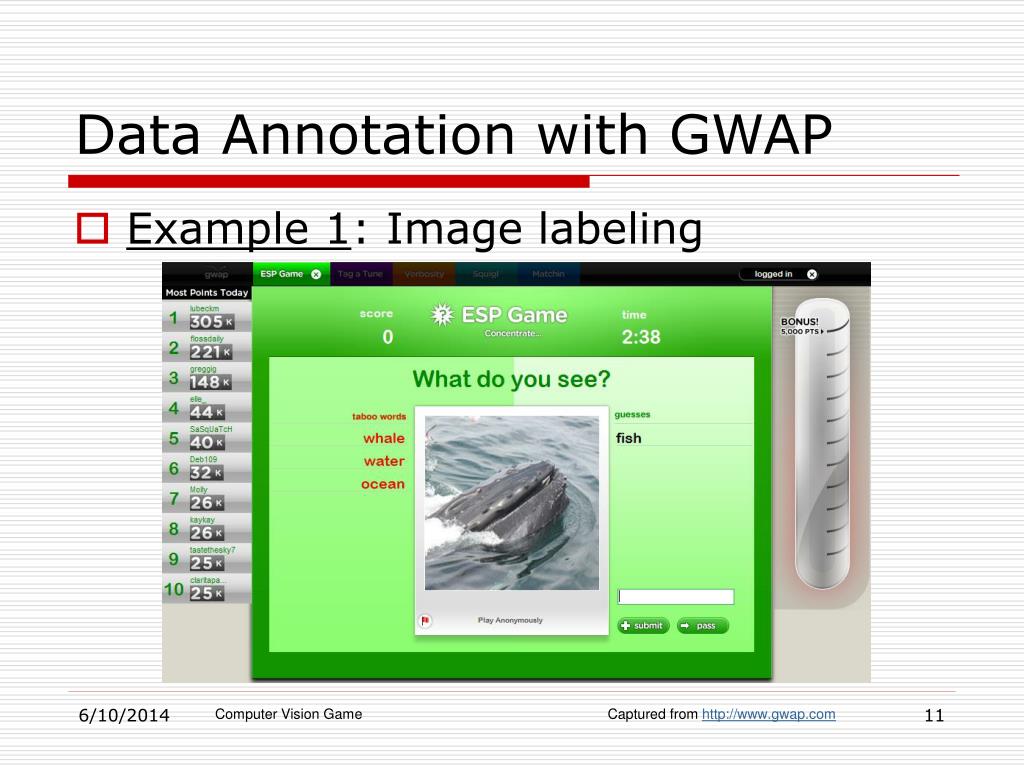
The role of image data annotation
Image data annotation has promoted the rapid development of computer vision. With the commercialization of various image detection and recognition algorithms, the market has become more and more strict about the accuracy of image annotation. At the same time, different image annotations have also been derived for different application scenarios. method. Ten Common Image Annotation Methods
Image data annotation is an essential step in supervised machine learning tasks. Garbage In Garbage Out is a commonly used phrase in the machine learning community, which means that the quality of the training data determines the quality of the model. The same goes for annotations for data annotation. If you show a child a tomato and say it’s a potato, the next time your child sees a tomato, he’s likely to classify it as a potato. Since machine learning models learn in a similar way, by looking at examples, the results of the model depend on the labels we input during the training phase.
In this article, we will introduce image annotation types, common annotation formats, and some tools that can be used for image data annotation.
Image annotation type

Before jumping into image data annotation, it is useful to understand the different image annotation types that exist in order to choose the correct type for your use case. Here are a few different types of callouts:
1.1, bounding box
Bounding boxes are the most commonly used type of annotation in computer vision. A bounding box is a rectangular box that defines the location of an object of interest. They can be identified by the x and y coordinates of the upper left corner of the rectangle and the x and y coordinates of the lower right corner of the rectangle. Bounding boxes are commonly used in object detection and localization tasks.
Bounding boxes of detected cars (original photo by Patricia Jekki on Unsplash)
A bounding box is usually represented by two coordinates (x1, y1) and (x2, y2) or by one coordinate (x1, y1) and a width (w) and height (h) of a bounding box.
Bounding box showing coordinates x1, y1, x2, y2, width (w) and height (h) (photo via an_vision on Unsplash)
1.2. Polygon segmentation
Polygon annotations are more precise, unlike rectangular frame annotations, which avoid visual model deviations caused by a large amount of white space and additional noise. Of course, polygon drawing requires more work, so the price will vary. Common polygon labeling applications include robot grabbing, medical image recognition, and satellite image recognition.
Image polygon segmentation from the COCO dataset (source)
1.3. Semantic Segmentation
Adding semantic labels to the segmented image (using different colors to represent different categories of objects) is to add labels to each type of object in the segmented image. These categories can be pedestrians, cars, buses, roads, sidewalks etc., each pixel has semantics, and the input is generally a color depth (RGB-D) image.
Semantic segmentation is mainly used in situations where environmental context is very important. For example, it is used in self-driving cars and robotics, as models learn about their environment.
Image semantic segmentation from the Cityscapes dataset (source)
1.4, 3D cuboid labeling
A 3D cuboid is similar to a bounding box with additional depth information about the object. Thus, using a 3D cuboid, you can obtain a 3D representation of an object, allowing the system to distinguish features such as volume and position in 3D space.
One use case for a 3D cuboid is in self-driving cars, where depth information can be used to measure the distance of objects from the car.
3D Cuboid annotation on image (original photo courtesy of Jose Carbajal on Unsplash)
1.5. Key point labeling
Keypoint annotation is used to detect small objects and shape changes by creating points on the image. This type of annotation is useful for detecting facial features, facial expressions, emotions, body parts, and poses.
1.6. Line labeling
Straight line labeling is mainly used for road recognition of self-driving vehicles, defining different roads such as vehicles, bicycles, traffic lights in the opposite direction, and forked roads.
Image Data Annotation Format
There is no single standard format when it comes to image annotation. The following are several commonly used annotation formats:
2.1COCO
COCO has five annotation types: for object detection, keypoint detection, footage segmentation, panorama segmentation, and image captioning. Annotations are stored using JSON.
For object detection, COCO follows the following format:
annotation {“id”: integer, “image_id”: int, “category_id”: int, “segmentation”: RLE or [polygon], “area”: float, “bbox”: [x,y,width,height], “iscrowd”: 0 or 1, } category[{“id”: int, “name”: str, “supercategory”: str, }] Pascal VOC: Pascal VOC stores callouts in XML files. Below is an example of a Pascal VOC annotation file for object detection.
<annotation>
<folder>Train</folder>
<filename>01.png</filename>
<path>/path/Train/01.png</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>224</width>
<height>224</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>36</name>
<pose>Front</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<occluded>0</occluded>
<bndbox>
<xmin>90</xmin>
<xmax>190</xmax>
<ymin>54</ymin>
<ymax>70</ymax>
</bndbox>
</object>
</annotation>
2.2YOLO

In the YOLO label format, .txt creates a file with the same name for each image file in the same directory. Each .txt file contains annotations of the corresponding image file, i.e. object class, object coordinates, height and width.
<object-class> <x> <y> <width> <height>
For each object, a new row is created.
Below is an example annotation in YOLO format, where the image contains two distinct objects.
0 45 55 29 67
1 99 83 28 44
Image Annotation Tool
Here is a list of tools available for annotating images:
1. Zhihu
2. Label image
3. VGG image tagger
4. Label
5. Scalable
6. Rectangular label
summarize
In this post, we introduce what data annotation /labeling is and why it is important for machine learning. We looked at 6 different types of image annotations: bounding boxes, polygon segmentation, semantic segmentation, 3D cuboids, keypoints and landmarks, lines and splines, and 3 different annotation formats: COCO, Pascal VOC, and YOLO. We also list some available image annotation tools.