 1")

Did you know annotation that almost 90% of the data an organization owns is unstructured and growing at a rate of 55-65% every year?
That must be a lot of unstructured data flowing! We all know how important high-quality training data is to AI/ML projects, not the fact that corrupting unstructured data poses security and compliance risks.
So, how to solve this problem, especially when building AI/ML models and must provide relevant information for the model to process and deliver output and inference? Well, the output of an AI and ML model is only as good as the data used to train it, because the model can only deliver effectively if the algorithm understands what the input is. Therefore, the accuracy of aggregating, labeling, and identifying data is critical. And this process of labeling, attributing or annotating data is called data labeling.
What is data annotation and how it can help companies implement foolproof AI/ML models
Data labeling is the classification and labeling of data in order to successfully deploy AI applications. Building AI or ML models with human-like behavior requires large amounts of high-quality data. This training data must be precisely classified and labeled for specific use cases to help companies build and improve AI implementations that enhance user experience.
Through data annotation, the AI model can correctly identify whether the received data is video, image, text, graphics, or a mixed format. Depending on the assigned parameters and the capabilities of the AI model, it will classify the data and continue to perform its task.
Data labeling ensures your models are trained accurately. So whether you’re deploying a model for speech recognition, automation, chatbots, or any other process, you’ll have a fully proven model that delivers the best results.
In ML, data labeling is responsible for identifying raw data (such as text files, images, and videos) with informative labels on it to train machine learning models. Data labeling can be applied to countless use cases such as natural language processing, computer vision, and speech recognition.
Data annotation is the process of labeling data with different forms of metadata (such as audio, text, images) to train ML models (such as chatbots, self-driving cars, etc.).
This is where the important role of “people in the loop” comes to the fore. Humans and human intelligence in the loop play a critical role in the process of validating, validating, and fixing problems in model results to improve efficiency and enable improvisation.
Therefore, data annotation and labeling can significantly enhance the capabilities of AI or ML programs while reducing time-to-market and total cost of ownership.
Data Annotation and Labeling – Scope of Application
High-quality data annotation and labeling is critical for a wide range of use cases across verticals. From healthcare to retail, from speech mining to text rendering for video conferencing, to optimizing traffic grids and more, data annotation and labeling is how AI and ML algorithms are entering the market.
Experts predict that from a $150 million market in 2018, data labeling will become a billion dollar industry by 2023 (Axois), and a $2.5 billion market by 2027.
Types of data annotations
To successfully execute the entire AI ML model learning process, it is critical to understand the different types of data annotation as required by a specific use case.
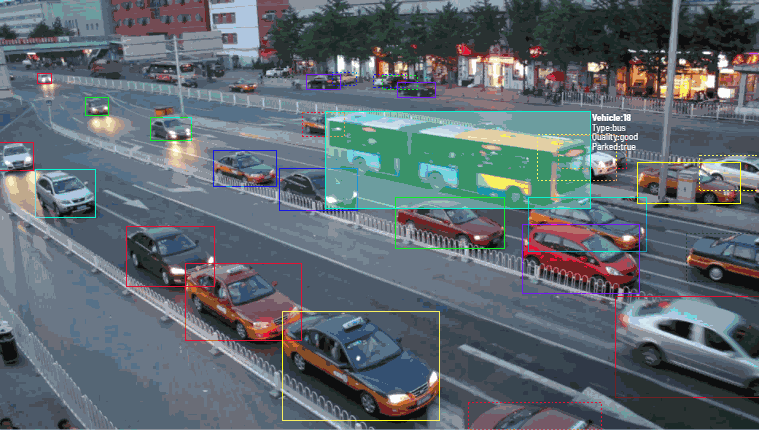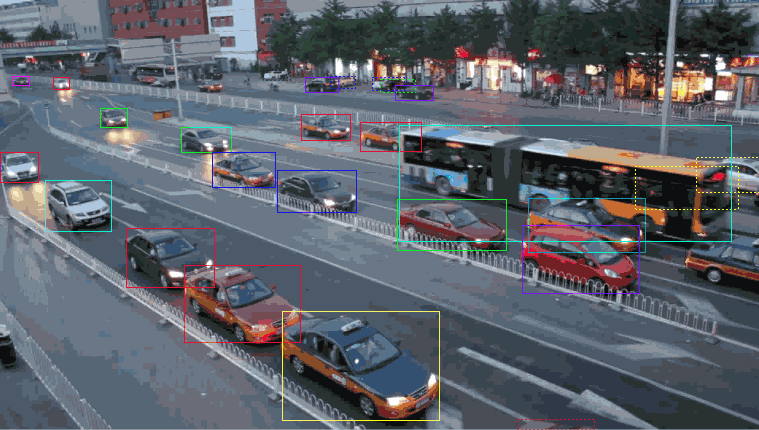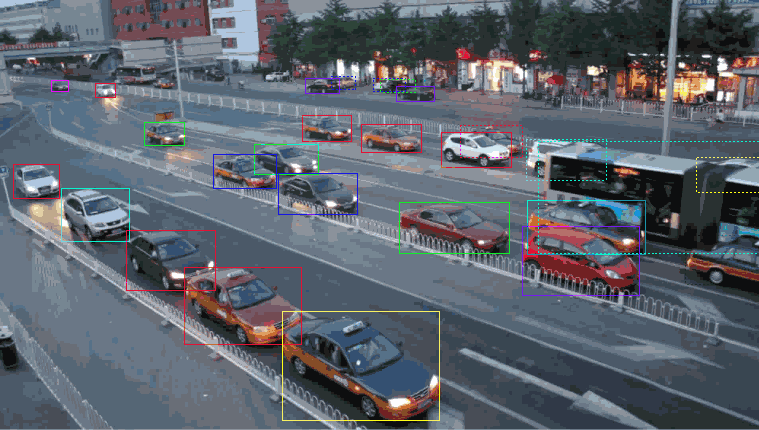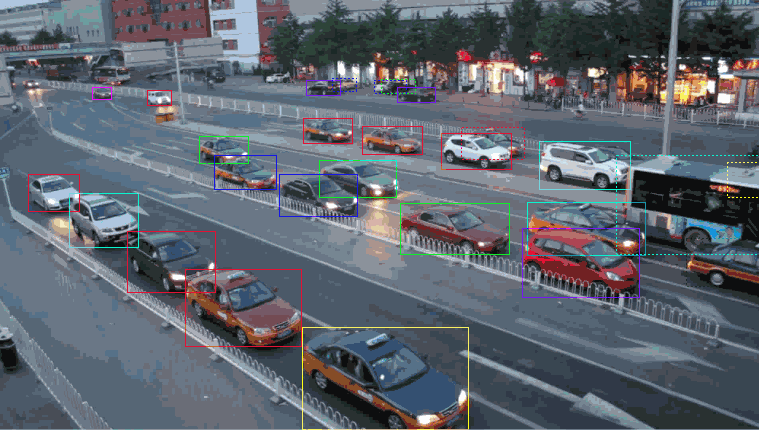
bounding box
A commonly used label data type is a bounding box. These boxes are mainly used to track objects for computer vision or validation and testing of new sensors. Let’s take self-driving cars as an example. Annotators will delineate bounding boxes around surrounding vehicles and label them accordingly. Such callouts and labels will help the algorithm understand what a particular vehicle/car looks like. Furthermore, bounding boxes improve automation efficiency while reducing costs.
3D cuboid
Cube Callout refers to drawing a cube on a specific or target object to obtain a 3D perspective of height, width, depth. Such annotations are widely used in road sequences to identify differences between roads, cars, trucks, vans, pedestrians, etc. A cuboid is drawn on the object, and the annotator just adjusts the size and size of the box.
Text annotation helps to train chatbots and assistant devices to answer questions from different users. Additionally, machine learning models are trained to create search engine-specific keywords and use them in key searches.
semantic annotation
Semantic annotation helps machine learning models train and understand annotation requirements by assigning each image pixel to a specific class of object. Semantic segmentation annotation is more general as it can easily distinguish objects like lanes, curbs, roads and identify instances from them throughout the sequence.
polyline callout
Polylines are responsible for labeling road lanes and other closed or open objects. Polyline callouts enable accurate path identification ahead of connected or autonomous vehicles. If we talk about the use or application of polylines, they perform well in self-tracking vehicles in high-definition maps and play an important role in training datasets for reliable self-driving models.
video annotation
Apart from detecting objects or recognizing them (such as image tagging), video annotation has various other uses. Video annotation trains ML models to localize human activity and estimate pose. In terms of self-driving cars, video annotation trains AI ML models to efficiently detect, recognize, classify, and localize different objects.
the bottom line

Data labeling and labeling are key to the development of AI ML learning. Around the world, people are already reaping the benefits of next-generation technologies such as artificial intelligence and machine learning. However, machine learning only works on relevant qualitative datasets, which is a very difficult task in the world of AI. With the rapid advancement of technology, every vertical business and industry worldwide requires data annotation to improve system quality and keep up with deep learning trends.