 1")
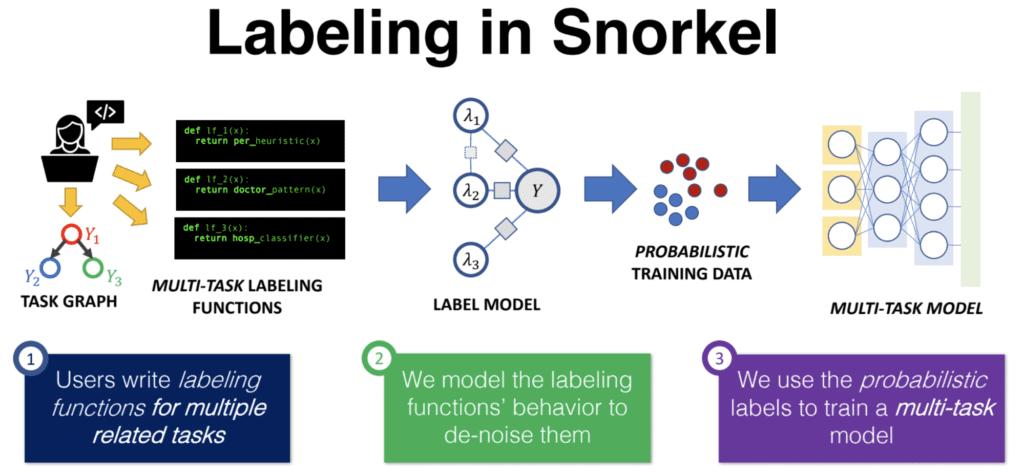
Introduction to Labeling Data
Data labeling is essential to innovations machine learning models, helping them learn and process information accurately. However, data labeling is a complex process requiring a team of experts and advanced technologies to achieve high-quality results. In today’s fast-paced world, new technologies and innovations continuously emerge, bringing revolutionary changes to the data labeling industry.
In this blog post, we will explore cutting-edge innovations and trends in data labeling, including using AI and crowdsourcing to improve the accuracy and efficiency of data labeling processes. We will also delve into the challenges and opportunities that come with the adoption of these new technologies, providing insights and recommendations for data labeling experts and enthusiasts.
Data labeling is an important part of supervised learning, which involves giving dataset labels with useful information. This step is very important because it gives us important information that helps us figure out the patterns and trends in the data. Correctly labeling data helps create useful datasets that can be used to train machine learning models. Data labeling has become more important in recent years as the need for complex machine learning algorithms that can do difficult tasks has grown.
Proper data labeling can help classify data into different categories, making it easier for machine learning algorithms to identify patterns and apply them in real-world scenarios. The overall effectiveness of data labeling affects the accuracy and performance of machine learning algorithms, which makes it an essential aspect of data processing. Therefore, data labeling is a vital part of any machine learning project, and proper labeling can be the difference between a successful and failed project.
Labeling data is crucial to working with datasets, as it plays a significant role in creating accurate models. Accurate labels in datasets ensure that the models created from them are as precise as possible. A few techniques can be used to label data, either manually or through automated processes, based on the size and complexity of the dataset.

Manual labeling involves annotating the data with labels by human experts, whereas automated labeling employs tools like Natural Language Processing (NLP) algorithms to label the data. Both techniques have advantages and disadvantages, and the choice of the labeling technique depends on the complexity, size, and nature of the problem to be solved. Regardless of the method chosen, accurate labels are critical for building precise models and extracting meaningful insights from large datasets. Therefore, it is essential to focus on labeling data accurately to ensure optimal results in data analysis and predictive modeling.
Again, labeling data is essential for developing effective machine-learning models. Labeling datasets is time-consuming and resource-intensive, but it is critical to creating high-quality models.
Labeled datasets provide a foundation of knowledge upon which machine learning algorithms can be trained to recognize patterns and make accurate predictions. This process saves time and resources and leads to more accurate results, thus improving the overall effectiveness of machine learning.
The importance of labeling data cannot be overstated, as it is fundamental to the success of machine learning models.
The Benefits of Accurate Labeling Data
Labeling data is an important part of making strong machine-learning models that can be used to solve problems in the real world. Accurate data labeling ensures that the models use relevant and up-to-date data, crucial for achieving the desired outcomes.
In addition to this, it helps reduce the amount of time required for training as well. Given the vast amounts of information available, labeling data is a vital process that requires precision and accuracy. With proper labeling, the data may be useful and accurate.
So, spending time and money on accurate data labeling processes is important to ensure that machine learning models are high-quality and can be used well for different purposes. Overall, appropriately labeling data is essential to achieving success in machine learning projects.
Finally, it is important to emphasize the significance of labeling data in any machine-learning task. When data is labeled correctly, machine learning models can be more accurate. -This makes it easier for them to find patterns and make accurate predictions.
As a result, the performance of machine learning algorithms increases significantly, and their accuracy becomes more refined. Understanding the importance of high-quality data and its impact on the success of machine learning algorithms is crucial.
Therefore, investing time and effort into labeling data accurately can improve the overall performance and accuracy of machine learning models, making them more effective and valuable for various applications.
The Benefits of Accurate Labeling Data: Enhancing Machine Learning and AI Applications
Introduction: Accurate labeling data is crucial for training machine learning models and developing reliable AI applications. The process of labeling data involves assigning meaningful and correct labels to various types of data, such as images, text, audio, and video. In this article, we will explore the benefits of accurate labeling data and its impact on machine learning and AI applications.
- Improved Model Performance: Accurate labeling data is the foundation for training high-performance machine learning models. When the labeled data accurately represents the ground truth or desired outcomes, the models can learn and generalize patterns effectively. The accuracy of the labeled data directly affects the performance of the models in tasks such as classification, object detection, sentiment analysis, and speech recognition. By ensuring accurate labeling, models can make more accurate predictions and produce reliable results.
- Enhanced Data Analysis: Accurate labeling data enables more meaningful and insightful data analysis. Labeled data provides valuable information for understanding trends, patterns, and correlations in the dataset. With accurate labels, analysts can perform in-depth analysis and gain insights into customer behavior, market trends, or operational patterns. Accurate labeling data facilitates informed decision-making, as organizations can make data-driven choices based on reliable and trustworthy data analysis.
- Improved User Experience: Accurate labeling data is instrumental in enhancing user experience in various AI applications. For example, in natural language processing applications, accurately labeled text data allows for more precise sentiment analysis, chatbot interactions, or language translation. In computer vision applications, accurate labeling enables object recognition, image segmentation, or augmented reality experiences. Accurate labeling data ensures that AI applications provide relevant, reliable, and personalized experiences to users, enhancing overall user satisfaction.
- Increased Efficiency and Automation: Accurate labeling data contributes to increased efficiency and automation in AI applications. With accurately labeled datasets, machine learning models can automate tasks that would otherwise require human intervention. For example, in document processing, accurate text annotation allows for automated document classification, information extraction, or sentiment analysis. Accurate labeling data enables the development of intelligent systems that can automate repetitive or labor-intensive tasks, saving time and resources for organizations.
- Reduced Bias and Fairness: Accurate labeling data helps address bias and promote fairness in AI applications. Biased or inaccurate labels can result in biased predictions or discriminatory outcomes. By ensuring accurate labeling, organizations can minimize biases and promote fairness in AI systems. Careful attention to the labeling process, diverse representation in the labeled data, and thorough quality control measures can help mitigate bias and ensure fairness in machine learning models and AI applications.
- Enhanced Data Privacy and Security: Accurate labeling data contributes to improved data privacy and security. When labeling data, sensitive information may be involved, such as personal health records, financial data, or confidential documents. By accurately labeling and properly anonymizing the data, organizations can ensure that privacy and security concerns are addressed. Accurate labeling data allows for the development of robust data protection strategies and compliance with data privacy regulations.
- Continuous Learning and Model Improvement: Accurate labeling data enables continuous learning and model improvement. As models are deployed and interact with real-world data, the feedback and outcomes can be used to refine and improve the models. Accurate labeling data helps identify areas of improvement, model weaknesses, or mislabeled instances. This feedback loop allows for iterative model refinement and continuous learning, leading to enhanced performance and adaptability of the models over time.
Conclusion: Accurate labeling data is essential for training robust machine learning models and developing reliable AI applications. It improves model performance, enhances data analysis, and enhances the user experience. Accurate labeling data contributes to increased efficiency, reduced bias, and improved data privacy and security. It also enables continuous learning and model improvement. By prioritizing accurate labeling data, organizations can unlock the full potential of machine learning and AI applications, leading to more accurate predictions, improved decision-making, and enhanced user satisfaction
The Benefits of Accurate Labeling Data: Enhancing Machine Learning and AI Applications
Introduction: Accurate labeling data plays a crucial role in training machine learning models and developing AI applications. Data annotation, which involves labeling data to provide reference points for algorithms, serves as the foundation for building robust and reliable models. In this article, we will explore the benefits of accurate labeling data and its impact on machine learning and AI applications.
- Improved Model Performance: Accurate labeling data leads to improved model performance. When machine learning models are trained on accurately labeled data, they can learn and generalize patterns effectively. Accurate labels provide the ground truth for models to identify and classify objects, recognize patterns, or make predictions. With precise and reliable labels, models can achieve higher accuracy, lower error rates, and better overall performance.
- Enhanced Prediction and Decision-Making: Accurate labeling data enables models to make more accurate predictions and informed decisions. Whether it’s classifying images, recognizing speech, or analyzing text sentiment, accurate labels provide the necessary guidance for models to make reliable predictions. Models trained on accurately labeled data can offer valuable insights and support decision-making processes in various applications, such as medical diagnosis, fraud detection, or customer sentiment analysis.
- Increased Efficiency and Productivity: Accurate labeling data contributes to increased efficiency and productivity in machine learning workflows. When models are trained on accurately labeled data, they require fewer iterations and adjustments during the training process. This reduces the time and resources required to develop and refine models. Moreover, accurate labels allow models to converge faster and achieve desired performance levels more efficiently, leading to shorter development cycles and faster deployment of AI applications.
- Enhanced Data Understanding: Accurate labeling data improves our understanding of the underlying data. When data is labeled accurately, it provides insights into the characteristics, distributions, and relationships within the dataset. This understanding helps identify potential biases, uncover hidden patterns, and gain a deeper knowledge of the data. Accurate labels provide context and structure, enabling researchers and practitioners to explore and analyze the data more effectively.
- Reliable Evaluation and Benchmarking: Accurate labeling data is crucial for evaluating and benchmarking machine learning models. Reliable evaluation requires labeled data with known ground truth to assess model performance objectively. Accurate labels allow for fair comparisons between different models, algorithms, or approaches. This ensures that the evaluation process is consistent and provides meaningful insights into the strengths and limitations of different models, enabling researchers to make informed decisions about model selection and optimization.
- Robust Generalization: Accurate labeling data facilitates robust generalization of machine learning models. Generalization refers to the ability of models to perform well on unseen or new data. When models are trained on accurately labeled data that captures diverse scenarios, they are more likely to generalize well to real-world situations. Accurate labels provide models with a comprehensive understanding of the data distribution, enabling them to handle variations, handle noise, and make accurate predictions even in previously unseen scenarios.
- Trust and Confidence in AI Applications: Accurate labeling data helps build trust and confidence in AI applications. When models consistently produce accurate and reliable results, users and stakeholders develop trust in the capabilities of AI systems. Trust is essential in various domains, such as healthcare, finance, or autonomous vehicles, where AI applications impact critical decisions and outcomes. Accurate labeling data plays a pivotal role in establishing trust by ensuring that AI systems operate reliably and deliver expected performance.
- Ethical Considerations and Fairness: Accurate labeling data is crucial for addressing ethical considerations and promoting fairness in AI applications. Biases or inaccuracies in labeling can result in biased or discriminatory outcomes. Accurate labels contribute to fair and unbiased decision-making by ensuring that models are trained on diverse and representative data. This helps mitigate biases and promotes equitable outcomes, particularly in applications such as hiring processes, loan approvals, or criminal justice systems.
Conclusion: Accurate labeling data offers numerous benefits to machine learning and AI applications. Improved model performance, enhanced prediction and decision-making, increased efficiency, and productivity are just a few of the advantages of accurate labeling data. It fosters a deeper understanding of the underlying data, enables reliable evaluation and benchmarking, supports robust generalization, and establishes trust and confidence in AI applications. Accurate labeling data is vital for ethical considerations and fairness, ensuring that AI systems operate in a transparent and unbiased manner. By recognizing the importance of accurate labeling data, we can build more reliable, trustworthy, and effective machine learning models, leading to advancements in various fields and domains.
Understanding Automated Labeling Data
Labeling data is crucial for businesses dealing with massive amounts of information. Accurately and consistently labeling data entails a considerable amount of time and resources, particularly in industries such as finance, healthcare, and customer service. -This is why automated data labeling has become essential for businesses to process their data more efficiently and accurately. Through automation, businesses can categorize, tag, and annotate their data significantly faster, eliminating the need for human labor.
Automated data labeling enables organizations to streamline their data annotation tasks, leading to more reliable analysis and insightful business decisions. The software algorithms that automate the process are designed to detect patterns and context, enabling them to categorize data based on pre-defined labels or keywords.
With automated data labeling tools, businesses can expect faster, more accurate, and more consistent labeling of large data sets, allowing them to extract valuable insights that can improve performance and competitive advantages.
Again, the importance of accurate data labeling cannot be overstated, as it forms the foundation for most machine learning models. Automated labeling presents an innovative solution to the challenges associated with manual data labeling.
Nonetheless, it is crucial to understand the intricacies of the automated data labeling process to ensure accurate results and prevent errors. Machine learning techniques such as artificial intelligence and natural language processing can significantly enhance the outcome of the labeling process.
Thus, leveraging these technologies can boost productivity and reliability while reducing the likelihood of mistakes, even in complex data sets. Automated data labeling is the future of managing large datasets efficiently and accurately.
Innovative Technologies for Labeling Data
The process of labeling data has been made easier and more efficient with the advances in technology. How we label data has greatly changed thanks to new technologies like artificial intelligence and natural language processing.
These automated solutions can quickly and accurately label a lot of data in less time than traditional methods.
-This has given us more time to do more complicated things, like analyze and explain the data. Automated labeling solutions have a lot of benefits, from making workers more productive to making labels more accurate and consistent. Technology has greatly enhanced the process of labeling data, making it easier, faster, and more accurate than ever before.
Labeling data is a critical process in artificial intelligence and machine learning. Deep learning algorithms have emerged as an effective means to label data accurately with minimal human intervention.
These algorithms can automatically understand the data and identify relevant labels by leveraging neural networks, natural language processing, and computer vision techniques.
This approach significantly reduces the manual labor associated with traditional data labeling methods, which can require numerous hours of human effort to annotate data accurately. Moreover, deep learning algorithms can learn from previous labeling tasks, improving accuracy and reducing the time required for subsequent tasks. As a result, deep learning algorithms for labeling data are becoming increasingly popular in industries like healthcare, finance, and retail, where large amounts of data need to be processed quickly and accurately.
Besides being a crucial step in data analysis, labeling data can be time-consuming and laborious. However, integrating machine learning methods and automated technologies such as facial recognition and natural language processing has revolutionized the process.
This integration has enabled faster and more accurate data labeling, a significant boost in the speed of data analysis while also increasing accuracy and precision. The benefits of these advancements are evident in various industries, from healthcare to finance, where data analysis plays a crucial role.innovations
The technologies mentioned above have substantially impacted labeling data, and their continued development will only lead to further enhancements in data analysis. Ultimately, machine learning and automated technologies are paramount to maximizing insights while minimizing downtime spent on manual data labeling tasks.innovations
Pros and Cons of Different Approaches to Labeling Data

Labeling data is a crucial aspect of machine learning, enabling algorithms to recognize patterns and make predictions based on past experiences. Adopting a supervised approach to data labeling can be highly beneficial, as it allows for more accurate and expansive training datasets that result in higher-quality models.innovations
This approach involves using human experts to manually label data points, providing clear and consistent annotations that can be used to train machine learning models.
By incorporating human input, supervised labeling can improve the accuracy of model predictions by reducing the risk of errors and ensuring that relevant features are identified.innovations
Additionally, this approach can increase the scalability of data labeling efforts, enabling researchers and data scientists to process larger datasets more efficiently.innovations
Overall, embracing a supervised approach to data labeling can yield significant improvements in the quality and effectiveness of machine learning models.
Data labeling is an essential process in machine learning, wherein data is categorized and annotated to help machines understand and recognize patterns. There are two broad approaches to data labeling: supervised and unsupervised. While the latter is often preferred due to its simplicity and cost-effectiveness, supervised approaches are known to deliver more accurate results.
However, one downside of supervised approaches is that they require extensive manual data labeling, which can be time-consuming and expensive. As such, organizations need to strike a balance between accuracy and efficiency when choosing between supervised and unsupervised data labeling approaches.innovations
To ensure that the labeling process is successful, organizations must invest in training their workforce and deploying sophisticated tools that can automate large parts of the process.innovations
The key to successful data labeling lies in having well-defined processes, skilled workers, and access to quality data.
Meanwhile, the need for accurately labeled data increases as machine learning models become more sophisticated and pervasive. However, labeling data can be a time-consuming and expensive process.innovations
A hybrid approach utilizing supervised and unsupervised techniques may balance accuracy and efficiency, allowing models to be trained quickly with minimal manual effort.innovations
Using unsupervised techniques can help reduce the need for extensive manual labeling, while supervised learning can provide the necessary precision for specific tasks.innovations
Combining these techniques makes it possible to create high-quality training datasets that provide both accuracy and efficiency, ensuring that the potential of machine learning is fully realized.innovations
Using hybrid labeling approaches can help organizations stay ahead in today’s data-driven landscape and ensure that they can efficiently develop models that meet their business needs.innovations
Preparing for the Future of Labeling Data innovations
Labeling data is a crucial process in preparing for the future of data management. With the increasing amount of data being generated, labeling has become essential to ensuring that the data is correctly classified and the insights generated are accurate. To keep up with this demand, organizations need to understand the powerful and cost-effective tools available to them today.innovations
Machine learning, natural language processing, and computer vision can significantly enhance and automate data labeling, improving accuracy and reducing time-to-market. By adopting these tools, organizations can significantly improve their ability to label large amounts of data accurately and efficiently, leading to enhanced productivity and better decision-making. As data becomes increasingly vital in business operations, investing in these tools will become critical to ensuring that organizations remain competitive and successful.innovations
Meanwhile, as businesses and industries continue to embrace machine learning and artificial intelligence, the importance of accurate data labeling becomes even more crucial. Investing in high-quality datasets and skilled human labor ensures the improved performance of machine-learning models and enhances the potential benefits of these technologies.innovations
With the need for precision and efficiency in data labeling, organizations should take the necessary steps to optimize their labeling practices by implementing a combination of technology and human intelligence. As we move into the future, the development of advanced machine learning technologies will heavily depend on the accuracy of the data used to train them, making effective data labeling more essential than ever.innovations
Conclusion
The data labeling industry is changing quickly, and to stay ahead of the competition, it is important to keep up with the latest trends and innovations. Adopting cutting-edge technologies such as AI and crowdsourcing can significantly improve the quality and speed of data labeling processes.innovations
However, new technologies also bring challenges, such as ensuring the privacy and security of sensitive data. -To succeed in this field, data labeling experts and enthusiasts must be adaptable and willing to embrace new ideas and methods. With careful consideration of opportunities and challenges, data labeling professionals can continue to drive innovation and push the boundaries of what’s possible in this exciting field. innovations.