 1")

There is a lot of dataset in the world. The hardest part is understanding it. How might be taken a dataset from simply existing to being a significant resource?
Data should be Findable, Open, Interoperable, and Reusable. Data that integrates FAIR data guidelines will basically influence laid out scientists. We ought to push science ahead with FAIR!
That all sounds awesome, yet how exactly could you anytime make data FAIR? We have several hints to start you off.
Depict any spot you can
Metadata matters. In case you’re introducing your data to a phase and there is suggested metadata, use it! This is an exceptional technique for giving information that you may not make sure to recollect for your own. Clients regularly drive the consolidation of explicit fields, so you can make your data more supportive and discoverable by using fields that have an exhibited history of redesigning datasets.
Illuminating title
We ought to move past final_FINAL_forRealThisTime_v5. That doesn’t instruct me anything in regards to your data aside from that you’ve battled with exchanging the right version. Keep your title conservative and enlightening. Recall that people looking at your dataset don’t have each of the settings that you have.
Clear keys
Have you anytime looked at a dataset and not had the choice to figure out what’s going on? Could we avoid that with your dataset? The best method for doing that is to use keys and names that seem, by all accounts, to be authentic to people other than yourself. Are there standard names in your space? Use them! Again, consider people who don’t have every one of the settings you have. Help them out so your data can be important to all.

Depiction and documentation
A general depiction of your dataset is exceptionally helpful. This can be associated with a README or anything that documentation you have open. In the event that someone wasn’t a piece of social occasion the data, they won’t have a lot of familiarity with your cycle and thusly, will not have even the remotest clue about the many-sided subtleties of the data (ie. that savvy shorthand you thought of or what unit of assessment you used). Contemplate including:
When and how the data was accumulated
- Size of the dataset
- Any dealing with you’ve done to the data
- Data fields and a depiction making sense of each field
- Explanations of any contractions and abbreviated structures
- Maker names, foundations, and contact information
- Think about various clients
Get your data to a place where someone other than yourself can use it. Come at the circumstance according to their point of view: accepting you were seeing this dataset strangely, how should you without a doubt use it? Set up the data that makes that possible.
Clean the dataset
Might it be said that you are using any sort of preprocessing step prior to using the data yourself? Killing duplicate qualities, taking out deficient segments, exchanging values over totally to a comparative unit of assessment, etc. Consider expecting this preprocessing will be useful to others and will make the data more usable.
Structure the dataset
In case applicable, adding development to your data can be unbelievably significant. Expecting you are adding development to your data to use it, think about keeping that construction while offering the data to others.
Data Prep Plan
At the Materials Data Office, we’ve seen what makes a data extraordinary and FAIR, and what doesn’t. Here is a plan that summarizes the concentrations above more minimally and comes right from our data rules. We’ve found that these standards enormously affect comfort and interpretability.
Our Dataset Rules at the Materials Data Office
- Give a README report and portrayal. This should portray the things in the data, the arrangement of the libraries, record naming plans, the size of the dataset, and associations with any associated circulations, codes, etc.
- Depict Data Provenance: Recollect for the portrayal, information about who, what, where, when, how, and why the data was assembled.
- Detail Data Quality: Record data combination procedures, endorsement strategies, and any known inclinations or cutoff points to give setting and sponsorship to clients.
- Use Open Record Associations: At whatever point what is going on permits, data should participate in plans that are open and clear by typical programming groups.
- Give Models: At whatever point what is happening permits, integrate occurrences of how to stack, research, and plot your data. These models could be associated with the store or associated in e.g., a GitHub vault.
- Detail Data Security and Moral Thoughts: Address any assurance concerns or moral considerations associated with the dataset, and ensure consistency with significant rules.
- Add Approving Information: Decide the license under which the data is scattered, identifying any utilization limits or necessities.
- Your dataset is endlessly ready for the world! By and by how might you share it?
Congratulations on setting up your dataset and detailed. That is troublesome work! Time to pick a phase to share your work.
Find a phase that looks at for sharing and getting to locally. Unsure where to start? Essentially enjoy the moment, we have two or three we recommend.

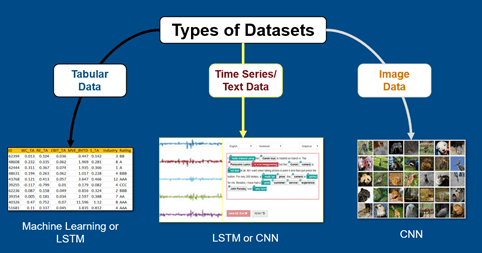
Dataset structure and properties are defined by the various characteristics, like the attributes or features. Dataset is generally created by manual observation or might sometimes be created with the help of the algorithm for some application testing. Data available in the dataset can be numerical, categorical, text, or time series. For example, in predicting the car price the values will be numerical. In the dataset, each row corresponds to an observation or a sample.
Datasets for Machine Learning and Artificial Intelligence are important to generate high-quality results. In order to achieve this, you need access to large amounts of data that meet all the requirements for your specific learning objective. This is often one of the most difficult tasks while working on a machine learning project.
At clickworker, we understand the importance of high-quality data and have gathered a large international crowd of 4.5 million Clickworkers who can help you prepare your datasets. We offer a wide variety of datasets in different formats, including text, images and videos. Best of all, you can get a quote for your customized Machine Learning Datasets by clicking on the link below. There are links to find out more about machine learning datasets, as well as information about our team of experts who can help you get started quickly and easily.