 1")
.jpeg "How Much Data Is Needed For a Best Machine Learning? 1")
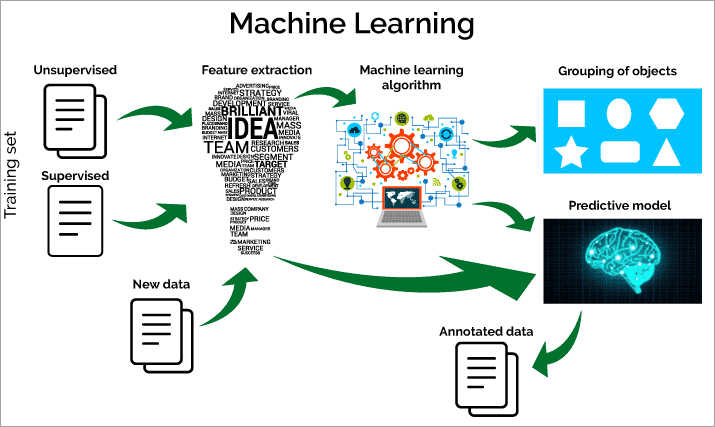
How Much Data Is Needed For Machine Learning?
Information is the soul of AI. Without information, it would be basically impossible to prepare and assess ML models. Yet, how much information do you really want for AI? In this blog entry, we’ll investigate the elements that impact how much information expected for a Machine learning project, systems to diminish how much information required, and tips to assist you with getting everything rolling with more modest datasets.
Machine learning (ML) and prescient examination are two of the main disciplines in current registering. Machine learning is a subset of computerized reasoning (man-made intelligence) that spotlights on building models that can gain from information as opposed to depending on unequivocal programming guidelines. Then again, information science is an interdisciplinary field that utilizes logical techniques, cycles, calculations, and frameworks to separate information and bits of knowledge from organized and unstructured information.
As Machine learning and information science have become progressively famous, one of the most generally posed inquiries is: how much information do you have to fabricate an AI model?
The solution to this question relies upon a few variables, for example, the
- type of problem being solved,
- the complexity of the Model,
- accuracy of the data,
- and availability of labeled data.
A guideline approach recommends that it’s ideal to begin with multiple times a bigger number of tests than the quantity of highlights in your dataset.

Furthermore, measurable strategies, for example, power examination can assist you with assessing test size for different sorts of AI issues. Aside from gathering more information, there are explicit methodologies to lessen how much information required for a Machine learning model. These incorporate element determination methods like Rope relapse or head part investigation (PCA). Dimensionality decrease methods like auto encoders, complex learning calculations, and engineered information age procedures like generative antagonistic organizations (GANs) are additionally accessible.
Albeit these strategies can assist with lessening how much information required for a Machine learning model, it is fundamental to recollect that quality actually matters more than amount with regards to preparing an effective model.
How Much Data is Needed?
Factors that influence the amount of data needed
When it comes to developing an effective machine learning model, having access to the right amount and quality of data is essential. Unfortunately, not all datasets are created equal, and some may require more data than others to develop a successful model. We’ll explore the various factors that influence the amount of data needed for machine learning as well as strategies to reduce the amount required.
Type of Problem Being Solved
The type of problem being solved by a machine learning model is one of the most important factors influencing the amount of data needed.
For example, supervised learning models, which require labeled training data, will typically need more data than unsupervised models, which do not use labels.
Additionally, certain types of problems, such as image recognition or natural language processing (NLP), require larger datasets due to their complexity.
The intricacy of the Model
Another element affecting how much information required for AI is the intricacy of the actual Model. The more intricate a model is, the more information it will expect to work accurately and precisely make forecasts or characterizations. Models with many layers or hubs will require more preparation information than those with less layers or hubs. Likewise, models that utilization various calculations, for example, troupe strategies, will require a bigger number of information than those that utilization just a solitary calculation.
Quality and Precision of the Information
The quality and precision of the dataset can likewise affect how much information is required for AI. Assume there is a great deal of commotion or wrong data in the dataset. All things considered, it could be important to build the dataset size to obtain exact outcomes from an AI model.
Also, assume there are missing qualities or anomalies in the dataset. All things considered, these should be either eliminated or credited for a model to work accurately; hence, expanding the dataset size is likewise vital.
Assessing how much information required
Assessing how much information required for AI (Machine learning) models is basic in any information science project. Precisely deciding the base dataset size required gives information researchers a superior comprehension of their Machine learning task’s degree, course of events, and plausibility.
While deciding the volume of information important for a Machine learning model, factors, for example, the sort of issue being addressed, the intricacy of the Model, the quality and precision of the information, and the accessibility of named information all become an integral factor.
Assessing how much information required can be moved toward in two ways:
- A rule-of-thumb approach
- or statistical methods
to estimate sample size.
Dependable guideline approach
The guideline approach is generally regularly utilized with more modest datasets. It includes speculating in light of previous encounters and current information. In any case, it is vital for utilize measurable strategies to appraise test size with bigger datasets. These strategies permit information researchers to work out the quantity of tests expected to guarantee adequate exactness and unwavering quality in their models.
Ongoing reviews show that around 80% of effective Machine learning projects use datasets with more than 1 million records for the purpose of preparing, with most using definitely a bigger number of information than this base edge.
Information Volume and Quality
While concluding how much information is required for AI models or calculations, you should consider both the volume and nature of the information required.
As well as meeting the proportion referenced above between the quantity of columns and the quantity of elements, it’s likewise essential to guarantee sufficient inclusion across various classes or classifications inside a given dataset, also called class lopsidedness or examining inclination issues. Guaranteeing a legitimate sum and nature of suitable preparation information will assist with decreasing such issues and permit expectation models prepared on this bigger set to accomplish higher precision scores over the long run without extra tuning/refinement endeavors later down the line.

General guideline about the quantity of lines contrasted with the quantity of highlights helps passage level Information Researchers conclude how much information they should gather for their ML projects.
In this manner guaranteeing that enough great info exists while executing AI procedures can go far towards staying away from normal traps like example predisposition and underfitting during post-sending stages. It is likewise accomplishing prescient capacities quicker and inside more limited advancement cycles, regardless of whether one approaches immense volumes of information.
Procedures to Diminish How much Information Required
Luckily, a few methodologies can diminish how much information required for a Machine learning model. Include determination procedures like head part investigation (PCA) and recursive element disposal (RFE) can be utilized to distinguish and eliminate excess highlights from a dataset.
Dimensionality decrease methods like particular worth deterioration (SVD) and t-dispersed stochastic neighbor implanting (t-SNE) can be utilized to lessen the quantity of aspects in a dataset while protecting significant data.
At long last, manufactured information age methods, for example, generative antagonistic organizations (GANs) can be utilized to create extra preparation models from existing datasets.
Tips to Lessen the Measures of Information Required for a ML Model
As well as utilizing highlight determination, dimensionality decrease, and engineered information age procedures, a few different tips can help section level information researchers lessen how much information required for their Machine learning models.
To start with, they ought to utilize pre-prepared models at whatever point conceivable since these models require less preparation information than custom models worked without any preparation. Second, they ought to consider utilizing move learning strategies which permit them to use information acquired from one assignment while settling one more related task with less preparation models.

At long last, they ought to attempt different hyperparameter settings since certain settings might require less preparation models than others.
Instances of Effective Activities with More modest Datasets
Information is a fundamental part of any AI project, and how much information required can shift contingent upon the intricacy of the Model and the issue being tackled.
In any case, it is feasible to accomplish successes with more modest datasets.
We will currently investigate a few instances of fruitful undertakings finished utilizing more modest datasets. Late overviews have demonstrated the way that numerous information researchers can finish effective tasks with more modest datasets.
Various instances of fruitful undertakings have been finished utilizing more modest datasets. For instance, a group at Stanford College utilized a dataset of just 1,000 pictures to make a simulated intelligence framework that could precisely analyze skin malignant growth.
One more group at MIT utilized a dataset of just 500 pictures to make a man-made intelligence framework that could distinguish diabetic retinopathy in eye scans.
These are only two instances of how strong AI models can be made utilizing little datasets.
Conclusion
Toward the day’s end, how much information required for an AI project relies upon a few variables, for example, the kind of issue being tackled, the intricacy of the Model, the quality and precision of the information, and the accessibility of marked information. To get a precise gauge of how much information is expected for a given undertaking, you ought to utilize either a guideline or factual techniques to work out example sizes. Furthermore, there are viable methodologies to diminish the requirement for huge datasets, like element determination strategies, dimensionality decrease procedures, and manufactured information age methods.
At last, fruitful activities with more modest datasets are conceivable with the right methodology and accessible advancements.