 1")
What is data labeling? The ultimate guide
Data labeling is interesting. Statistical labeling is an important factor for school devices to master models and ensure that they can adequately perceive various objects in the physical world. Categorized data plays an important role in improving ML models as it will determine the overall accuracy of the system itself. To help you better label records, we created this data labeling manual to help you better accomplish your challenge.
What is fact labeling?
Record tagging, in the context of device control, is the act of recognizing raw information (images, text documents, movies, etc.) and adding one or more applicable and meaningful tags to provide context, allowing a device read model to learn from statistics. Tags can also indicate, for example, the words spoken in an audio recording, the presence of a car or a bird in an image, or the presence of a tumor in an x-ray. For many use cases, including speech recognition, natural language processing, and computer vision, data labeling is essential.
Why use record tagging?
For a machine learning model to perform a given task, it needs to navigate or understand its environment properly. This is where the stat tag element comes into play because this is exactly what tells the version what an element is. Software stakeholders should be aware of the security level of a release in their predictions that AI models will apply in real global programs. It is very important to ensure that employees interested in the labeling process are being evaluated for first-class assurance purposes, as this will be traced back to the record labeling level.
How does data labeling work?
Now that we know what classified records are, we can move on to how the entire system works. We can summarize the labeling process in four elements:
Data Series: This is the procedure for gathering the records that you want to tag, such as photos, movies, audio clips, etc.
Record Tagging: For the duration of this technique, statistical annotators can tag all elements of the hobby with a corresponding tag to allow ML algorithms to understand the information.
Satisfactory Guarantee – The QA team can review all work done through the Stat Scorers to ensure everything was done efficiently and the desired metrics were achieved.
Model education: Categorized data is used to train the version and help it meet the desired obligations more exceptionally.
main types of statistics Labeling
When labeling data sets, there are predominant types of data labeling:
Computer vision: This branch of computing specializes in giving machines the ability to capture and recognize objects and those that appear in photographs and movies. Like other types of artificial intelligence, computer vision seeks to execute and mechanize sports that mimic human abilities.

NLP: With the use of natural language processing (NLP), computers can now understand, manipulate and interpret human language. Large amounts of text and speech data are now being collected with the help of organizations across a variety of conversational channels, including emails, text messages, social media news feeds, audio, video, and more.
Advantages of Labeling statistics
We know what tag statistics are, but what are the advantages of doing it? Here are some of the benefits of labeling your information.
Specific predictions: With well-categorized information, your device knowledge will have greater context about educational data sets, which in turn will allow you to gain greater insights and provide better predictions.
Advanced Statistics Usability: Thanks to information tagging, systems study systems are better able to map an input to a particular output, which is more beneficial for the ML system and end customers.
Best Excellent Version: The better the quality of the labeled educational data sets, the higher the overall quality of the ML system can be.
Challenges of Fact Labeling
While fact labeling is indeed a critical process, there are also many obstacles to pay attention to:
Understanding of the area: It is very important that all data annotators have considerable experience not only in labeling simple records, but also in the company for which the task is performed. This can help you get the necessary fine stages.
Restricting useful resources: It can be difficult to ensure that annotators have experience with challenges in specialized industries such as healthcare, finance, or scientific research. Wrong annotations due to lack of area knowledge can also affect the performance of the model in practical situations.
Label inconsistency: A traditional hassle is maintaining regular labels, especially in collaborative or crowdsourced labeling tasks. The data set may also contain noise due to inconsistent labeling, which would affect the version’s ability to generalize correctly.
Done right: Release results are generated immediately based on the quality of the categorized information. Model reliability depends on ensuring that labels, as they should be, represent real-world situations and resolving issues such as mislabeling and outliers.
Data Protection: Preventing privacy violations during the labeling process requires safeguarding sensitive data. Data security requires the use of strong safeguards, including encryption, access controls, and compliance with data protection laws.
What are some exceptional practices for information labeling?
Developing reliable device learning models requires excellent log labeling examples. Your moves during this level greatly impact the effectiveness and quality of the build. Choosing an annotation platform is vital to success, especially if it has an easy-to-use interface. Those platforms improve information labeling accuracy, productivity, and personal experience.
Intuitive interfaces for taggers: To make statistics tagging targeted and green, taggers must have interfaces that can be intuitive and easy to use. These interfaces speed up the process, reduce the potential for labeling errors, and improve customers’ information annotation experience.
Collect numerous data: You should ensure that you have a wide variety of record samples in your educational data sets to ensure that the ML device can locate the desired objects or efficiently understand numerous text strings.
Acquire specific/representative data: An ML model will need to perform a wide variety of duties, and you will need to provide it with categorized real-world information that gives it the facts it needs to understand what that task is and how to perform it. achieve it.
Tag Audit: It is essential to periodically validate categorized data sets in order to discover and resolve issues. It involves reviewing categorized information to look for biases, inconsistencies or errors. The audit ensures that the labeled data set is honest and tailored to the device that dominates the company’s desires.
Establish a guiding annotation principle: It is essential to have a conversation with the fact annotation company to ensure they understand how statistics should be classified. Having a guide for nearby groups will be a great reference point if there are any questions.
Establish a quality control procedure: As we noted above, the better the accuracy of the labeled data, the better the accuracy of the final product can be. Consequently, it is anyone’s job to ensure that all statistics labeling tasks are completed correctly the first time.
Key takeaways
The old saying “garbage in, garbage out” clearly applies to systemic learning. Because the input data immediately affects the effectiveness of the latest version, data labeling is a vital part of training device-domain algorithms. Increasing the number and caliber of training records may actually be the most practical method of improving a ruleset. The labeling task is also here to stay due to the growing popularity of the system.
Data labeling is a cornerstone of the device domain, addressing an essential task in artificial intelligence: transforming raw statistics into machine-intelligible design.
In essence, file annotation solves the problem presented by unstructured files: machines struggle to recognize the complexities of the real world because they lack human cognition.
In this interplay between facts and intelligence, data tagging takes on the role of an orchestrator, imbuing raw statistics with context and meaning. This blog explains the importance, methodologies and demanding situations associated with fact labeling.
Knowledge Data Labeling
In the device domain, statistics is the fuel that powers algorithms to decipher patterns, make predictions, and improve decision-making techniques. but now not all the facts are identical; Ensuring that a device acquires knowledge of its task depends on the meticulous record labeling procedure, a challenge similar to presenting a roadmap for machines to navigate the complexities of the real world.
What is record tagging?
Information labeling, often called record annotation, involves the careful tagging or marking of data sets. These annotations are the signals that the handheld device gets to know the models during its educational segment. As models analyze from categorized facts, the accuracy of these annotations directly affects the model’s potential to make particular predictions and classifications.
Importance of Statistics Labeling in device control data annotation or labeling provides context for records that system learning algorithms can recognize. Algorithms learn to understand styles and make predictions based primarily on categorized data. The importance of data labeling lies in its ability to beautify the learning system, allowing machines to generalize from categorized examples to make informed decisions on new, unlabeled data.
Correct and well-categorized sets of information contribute to creating solid and reliable devices for understanding trends. Those models, whether for photo reputation, natural language processing, or other programs, rely heavily on classified statistics to identify and differentiate between different input styles. The quality of data labeling directly affects the overall performance of the model, influencing its accuracy, thoughtfulness, and overall predictive capabilities.
In industries like healthcare, finance, and autonomous driving, where the stakes are high, the accuracy of machine learning models is critical. Properly labeled records ensure that models can make informed selections, improving efficiency and reducing errors.
How do data labeling paints work?
Understanding the intricacies of how statistical labeling works is critical to determining its impact on machine learning models. This section discusses the mechanics of log labeling, distinguishes between categorized and unlabeled data, explains log collection techniques, and discusses the labeling method.
Labeled Data vs. Unlabeled Data
Within the dichotomy of supervised and unsupervised device learning, the distinction lies in the presence or absence of labeled information. Supervised knowledge thrives on categorized statistics, where each example within the educational set is matched with a corresponding outcome label. This labeled information will become the version’s model, guiding it to learn the relationships and patterns vital to correct predictions.
In contrast, unsupervised knowledge acquisition operates within the realm of unlabeled information. The ruleset navigates the data set without predefined labels, looking for inherent styles and systems. Unsupervised mastering is a journey into the unknown, where the set of rules must find the latent relationships within the facts without explicit direction.
Statistical series techniques
The technique of fact labeling begins with the purchase of statistics, and the strategies employed for this cause play a fundamental role in shaping the best and most varied collection of labeled data.
Manual data collection,
one of the most conventional yet effective strategies, is the guideline data series. Human annotators meticulously label data points based on their knowledge, ensuring accuracy in the annotation process. While this method guarantees 86f68e4d402306ad3cd330d005134dac annotations, it can be time-consuming and useful in depth.
Dataset annotation – 24x7offshoring
Open Source Datasets
In the era of collaborative knowledge sharing, leveraging open source data sets has become a popular strategy. These data sets, categorized by a community of specialists, offer a cost-effective way to access extensive and appropriately annotated information for school system learning models.

Era of artificial statistics
To cope with the adventure of restricted, real and international labeled facts, the technology of artificial facts has gained importance. This technique involves creating artificial information factors that mimic real international eventualities, increasing the labeled data set and improving the version’s ability to generalize to new, unseen examples.
Record Labeling System
The way data is labeled is an important step that requires attention to detail and precision to ensure that the resulting classified data set correctly represents the real-world international scenarios that the model is expected to encounter.
Ensuring Information Security and Compliance
With increased concerns about data privacy, ensuring the security and compliance of labeled information is non-negotiable. It is essential to implement strict measures to protect confidential information during the labeling process. Encryption, access controls, and compliance with data security standards are important additions to this security framework.
Facts Manual Labeling Techniques Labeling
System
The manual form of labeling involves human annotators meticulously assigning labels to statistical points. This technique is characterized by its precision and attention to detail, ensuring annotations that capture the complexities of real international situations. Human annotation brings expertise to the labeling process, allowing for nuanced distinctions that computerized systems may struggle to address.
Manual labeling process – 24x7offshoring
However, the manual procedure can be time- and resource-consuming, requiring robust and satisfactory handling measures. Quality management is vital to select and rectify any discrepancies in annotations, maintaining the accuracy of the categorized data set. Organizing a ground truth, a reference point against which the annotations are compared, is a key element in a first-level control, as it allows the consistency and accuracy of the annotations to be evaluated.

Semi-Supervised Labeling Semi-supervised
labeling achieves stability between classified and unlabeled facts, taking advantage of the strengths of both. Energy awareness, a form of semi-supervised labeling, involves the version actively selecting the maximum factors of informative records for labeling. This iterative process optimizes the development cycle, focusing on areas where the known version shows uncertainty or requires more information. Combined tagging, another aspect of semi-supervised tagging, integrates categorized and untagged statistics to beautify release performance.
Artificial Information Labeling
Artificial information labeling involves the development of artificial information factors to complement categorized real-world data sets. This method addresses the task of constrained labeled facts by producing numerous examples that increase the model’s knowledge of numerous situations. While artificial facts are a valuable aid to fashion education, it is crucial to ensure their relevance and compatibility with real international information.
Automated Fact Tagging
Automatic Fact Tagging – 24x7offshoring
Computerized statistical labeling employs algorithms to assign labels to statistical factors, simplifying the labeling procedure. This method greatly reduces the guidance effort required, making it efficient for large-scale labeling responsibilities. However, the achievement of automatic labeling depends on the accuracy of the underlying algorithms, and exceptional management measures must be implemented to rectify any mislabeling or inconsistencies.
Animated study and energy awareness is a dynamic technique in which the model actively selects the most informative statistical points for labeling. This iterative method optimizes the study method, directing attention to regions where version uncertainty prevails or where additional records are important.
Animated Mastering
Energy mastering
The active domain improves performance by prioritizing fact labeling that maximizes model information.
Learn more about the live video The Future of Machine Learning Teams: Embracing Active Learning
Outsourcing Labeling
Outsourcing log labeling to specialized service providers or crowdsourcing platforms offers scalability and cost-effectiveness. This approach allows agencies to directly access a distributed workforce to annotate large volumes of records. While outsourcing improves efficiency, preserving best-in-class management and ensuring consistency among scorers are critical challenges.
Collaborative Tagging
Collaborative tagging leverages the collective efforts of a distributed online workforce to annotate records. This decentralized technique provides scalability and diversity, but requires careful control to address label consistency and good control capacity issues.
Careful plans need to be made to navigate the wide range of fact-labeling strategies while thinking about desires, sources, and desired level of task manipulation. Striking the right balance between automated efficiency and manual precision is critical to meeting the data labeling challenge.
Types of Information Labeling
Information labeling is flexible enough to accommodate the many needs of device study applications. This phase explores the various record tagging techniques tailored to precise domain names and applications.
Vision and Computer Vision Labeling
Supervised Study
Supervised study bureaucracy the backbone of vision labeling and computer vision. In this paradigm, fashions are educated on classified data sets, in which each photo or video frame is matched with a corresponding label. This matching allows the model to investigate and generalize patterns, making correct predictions about new, unseen records. Supervised learning programs in computer vision include photo classification, object detection, and facial recognition.
Unsupervised mastering
In unsupervised getting to know for laptop vision, fashions perform on unlabeled records, extracting styles and structures without predefined labels. This exploratory approach is in particular beneficial for responsibilities that discover hidden relationships within the facts. Unsupervised getting to know packages consist of clustering comparable images, photo segmentation, and anomaly detection.
Semi-supervised learning
Semi-supervised gaining knowledge of balances categorised and unlabeled records, offering the benefits of each strategies. active learning, a technique within semi-supervised labeling, involves the model selecting the most informative facts points for labeling. This iterative method optimizes getting to know by using specializing in areas where the version reveals uncertainty or calls for additional facts. mixture labeling integrates labeled and unlabeled facts, enhancing model overall performance with a greater big dataset.
Human-in-the-loop (HITL) labeling acknowledges the strengths of both machines and humans. whilst machines cope with ordinary labeling obligations, people intrude whilst complex or ambiguous eventualities require nuanced choice-making. This hybrid approach guarantees the high-quality and relevance of classified facts, particularly whilst automatic structures war.
Programmatic statistics labeling
Programmatic records labeling includes leveraging algorithms to robotically label statistics based totally on predefined rules or styles. This computerized approach streamlines the labeling method, making it efficient for huge-scale datasets. however, it calls for cautious validation to make sure accuracy, because the fulfillment of programmatic labeling depends on the first-rate of the underlying algorithms.
24x7offshoring includes figuring out and classifying entities within textual content, which include names of human beings, places, groups, dates, and more. 24x7offshoringis essential in extracting established statistics from unstructured textual content, enabling machines to understand the context and relationships between entities.
Sentiment analysis
Sentiment evaluation aims to determine the emotional tone expressed in textual content, categorizing it as fine, terrible, or neutral. This method is vital for customer comments evaluation, social media tracking, and marketplace research, providing valuable insights into consumer sentiments.
Textual content category
text type includes assigning predefined categories or labels to textual information. This method is foundational for organizing and categorizing big volumes of text, facilitating automated sorting and data retrieval. It unearths applications in spam detection, subject matter categorization, and content advice systems.
Audio Processing Labeling
Audio processing labeling includes annotating audio data to train models for speech popularity, audio event detection, and various other audio-primarily based applications. right here are a few key forms of audio-processing labeling techniques:
Velocity statistics labeling
Speech information labeling is essential for education fashions in speech recognition structures. This technique includes transcribing spoken phrases or terms into text and developing a categorised dataset that paperwork the idea for education correct and efficient speech recognition fashions. 86f68e4d402306ad3cd330d005134dac speech facts labeling ensures that fashions apprehend and transcribe diverse spoken language styles.
Audio occasion labeling
Audio event labeling focuses on identifying and labeling specific events or sounds inside audio recordings. this can encompass categorizing occasions which includes footsteps, automobile horns, doorbell jewelry, or any other sound the version wishes to apprehend. This technique is precious for surveillance, acoustic monitoring, and environmental sound evaluation programs.
Speaker diarization
Speaker diarization includes labeling unique speakers inside an audio recording. This manner segments the audio circulation and assigns speaker labels to every section, indicating whilst a selected speaker starts and ends. Speaker diarization is essential for applications like assembly transcription, which enables distinguish among distinct speakers for a more correct transcript.
Language identification
Language identity entails labeling audio data with the language spoken in every segment. that is mainly relevant in multilingual environments or programs in which the version must adapt to one of a kind languages.
Benefits of statistics Labeling
The system of assigning significant labels to facts points brings forth a mess of benefits, influencing the accuracy, usability, and universal quality of system gaining knowledge of models. right here are the important thing advantages of statistics labeling:
Specific Predictions
categorized datasets serve as the education ground for device mastering models, allowing them to learn and recognize patterns within the records. The precision of these patterns without delay affects the version’s potential to make correct predictions on new, unseen information. nicely-categorised datasets create models that may be generalized successfully, main to more specific and reliable predictions.
Stepped forward records Usability
nicely-organized and classified datasets enhance the usability of information for system mastering duties. Labels offer context and shape to raw records, facilitating green version training and making sure the discovered styles are relevant and relevant. stepped forward facts usability streamlines the machine mastering pipeline, from facts preprocessing to model deployment.
Improved model first-rate
The nice of labeled records without delay affects the exceptional of device studying models. 86f68e4d402306ad3cd330d005134dac labels, representing accurate and meaningful annotations, make a contribution to growing sturdy and dependable models. fashions trained on nicely-labeled datasets show off stepped forward performance and are better ready to address actual-global scenarios.
Use instances and programs
As discussed earlier than, for plenty gadget gaining knowledge of packages, statistics labeling is the foundation that permits fashions to traverse and make knowledgeable decisions in various domains. records points may be strategically annotated to facilitate the introduction of wise structures which can respond to particular requirements and issues. the following are use instances and applications where facts labeling is critical:
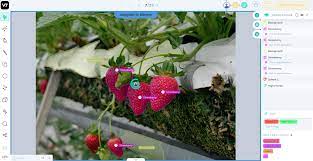
Picture Labeling
picture labeling is crucial for education fashions to apprehend and classify items inside photographs. this is instrumental in packages consisting of self sufficient automobiles, in which figuring out pedestrians, vehicles, and street symptoms is essential for safe navigation.
Text Annotation
textual content annotation includes labeling textual statistics to permit machines to apprehend language nuances. it is foundational for packages like sentiment analysis in consumer comments, named entity recognition in text, and textual content category for categorizing documents.
Video records Annotation
Video information annotation enables the labeling of objects, actions, or occasions within video sequences. this is crucial for applications together with video surveillance, where fashions need to locate and track objects or understand unique activities.
Speech statistics Labeling
Speech records labeling entails transcribing spoken phrases or phrases into text. This categorized information is vital for schooling correct speech recognition fashions, enabling voice assistants, and enhancing transcription offerings.
Medical facts Labeling
medical data labeling is important for responsibilities which includes annotating scientific pix, helping diagnostic procedures, and processing patient statistics. labeled clinical data contributes to advancements in healthcare AI applications.
Demanding situations in statistics Labeling
while statistics labeling is a fundamental step in developing robust device mastering fashions, it comes with its challenges. Navigating these challenges is crucial for ensuring the first-rate, accuracy, and equity of labeled datasets. here are the key demanding situations in the information labeling process:
Area information
ensuring annotators own area know-how in specialised fields consisting of healthcare, finance, or clinical research can be hard. lacking domain information may additionally result in faulty annotations, impacting the version’s overall performance in real-world scenarios.
aid Constraint
information labeling, specially for massive-scale projects, can be aid-in depth. acquiring and managing a skilled labeling personnel and the important infrastructure can pose challenges, leading to capacity delays in project timelines.
Label Inconsistency
retaining consistency throughout labels, especially in collaborative or crowdsourced labeling efforts, is a commonplace venture. Inconsistent labeling can introduce noise into the dataset, affecting the version’s ability to generalize as it should be.
Labeling Bias
Bias in labeling, whether or not intentional or accidental, can lead to skewed fashions that won’t generalize nicely to various datasets. Overcoming labeling bias is important for constructing fair and impartial gadget gaining knowledge of structures.
Statistics quality
The nice of labeled facts at once impacts version outcomes. making sure that labels appropriately constitute real-international situations, and addressing issues such as outliers and mislabeling, is essential for model reliability.
statistics protection
shielding touchy facts at some stage in the labeling system is imperative to save you privateness breaches. implementing sturdy measures, such as encryption, get right of entry to controls, and adherence to statistics safety rules, is essential for maintaining information security.
Overcoming those demanding situations calls for a strategic and considerate approach to records labeling. implementing exceptional practices, making use of advanced equipment and technology, and fostering a collaborative surroundings among area experts and annotators are key techniques to cope with those challenges efficaciously.
First-class Practices in statistics Labeling
records labeling is vital to developing robust device learning fashions. Your practices in the course of this section considerably impact the model’s fine and efficacy. A key success issue is the choice of an annotation platform, in particular one with intuitive interfaces. these systems decorate accuracy, efficiency, and the person experience in information labeling.
Intuitive Interfaces for Labelers
supplying labelers with intuitive and person-pleasant interfaces is vital for green and correct statistics labeling. Such interfaces lessen the likelihood of labeling errors, streamline the system, and enhance the information annotation experience of customers. Key functions like clear commands with ontologies, customizable workflows, and visual aids are fundamental to an intuitive interface.
Label Auditing
frequently validating labeled datasets is crucial for figuring out and rectifying mistakes. It involves reviewing the categorized statistics to locate inconsistencies, inaccuracies, or potential biases. Auditing guarantees that the labeled dataset is reliable and aligns with the intended objectives of the device learning project.
A robust label auditing exercise have to possess:
- excellent metrics: To swiftly scan large datasets for errors.
- Customization options: Tailor checks to particular venture requirements.
- Traceability functions: tune changes for transparency and accountability.
- Integration with workflows: Seamless integration for a smooth auditing technique.
- Annotator management: Intuitive to control and manual the annotators to rectify the mistakes
- those attributes are functions to search for in a label auditing device. This manner may be a useful asset in maintaining records integrity.
- mild-callout-cta
Tractable’s adoption of a24x7offshoring and overall performance tracking platform exemplifies how systematic auditing can hold information integrity, mainly in big, far off teams. See how they do it in this example study. - energetic learning procedures
- lively getting to know tactics, supported by way of intuitive structures, improve records labeling efficiency. those techniques enable dynamic interaction between annotators and
- fashions. unlike traditional methods, this approach prioritizes labeling times where the model is uncertain, optimizing human effort for tough information points. This symbiotic
- interplay complements efficiency, directing sources to refine the model’s information in its weakest areas. also, the iterative nature of lively getting to know guarantees continuous
- development, making the gadget mastering machine step by step adept at coping with diverse and complicated datasets. This method maximizes human annotator information
- and contributes to a extra efficient, specific, and adaptive data labeling technique.
Exceptional Management Measures with 24x7offshoring
Encord stands out as a complete answer, providing a set of excellent control measures designed to optimize all aspects of the way data is labeled. Here are some high-quality measurements:
Animated Learning Optimization
, which ensures ideal release performance and facilitates iterative mastering, is critical in machine learning initiatives. Encord’s excellent control measures include active mastering optimization, a dynamic function that ensures the best model performance, and iterative learning. By dynamically identifying difficult or unsafe moments, the platform directs annotators to learn specific record factors, optimizing the learning process and improving model efficiency.
Animated Mastering Optimization – 24x7offshoring
Addressing Annotation Consistency
Encord recognizes that annotation consistency is paramount for categorized data sets. To address this, the platform meticulously labels statistics, has workflows to verify labels, and uses exceptional label metrics to detect identity errors. With an awareness committed to minimizing labeling errors, 24x7offshoring ensures that annotations are reliable and provide categorized data that is precisely aligned with the challenge objectives.
Ensuring record accuracy , validation, and successful data assurance are the cornerstones of Encord’s world-class handling framework. By applying various high-quality statistics, metrics, and ontologies, our platform executes robust validation methods, safeguarding the accuracy of classified information. This commitment ensures consistency and the best standards of accuracy, strengthening the reliability of machine learning models.